
This post is the second in a series on getting started with the AWS DeepLens. In Part 1, we introduced a program that could detect faces and crop them by extending the boilerplate Greengrass Lambda and pre-built model provided by AWS. This focussed on the local capabilities of the device, but the DeepLens device is much more than that. At its core, DeepLens is a fully fledged IoT device, which is just one part of the 3 Pillars of IoT: devices, cloud and intelligence.
All code and templates mentioned can be found here. This can be deployed using AWS SAM, which helps reduces the the complexity for creating event-based AWS Lambda functions.
Sending faces to IoT Message Broker
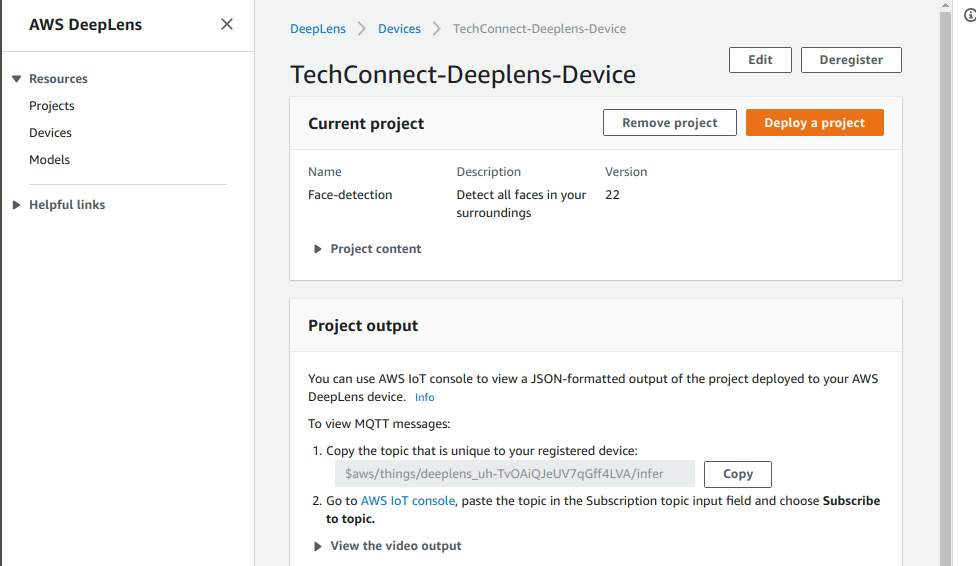
When registering a DeepLens device, AWS creates all things associated with the IoT cloud pillar . If you have a look for yourself in the IoT Core AWS console page, you will see existing IoT groups, devices, certificates, etc.. This all simplifies the process of interacting with the middle-man, the MQTT topic that is displayed on the main DeepLens device console page. The DeepLens (and others if given authorisation) has the right to publish messages to the IoT topic within certain limits.
Previously, the AWS Lambda function responsible for detecting faces only showed them on the output streams and was only publishing to the MQTT topic the threshold of detected faces. We can modify this by including cropped face images as part of the packets that are sent to the topic.
The Greengrass function below extends the original version by publishing a message for each detected face. Encoded cropped face images are set in the “image_string” key of the object. IoT messages have a size limit of 128 KB, but the images will be well within the limit and encoded in Base64.
# File "src/greengrassHelloWorld.py" in code repository
from threading import Thread, Event
import os
import json
import numpy as np
import awscam
import cv2
import greengrasssdk
class LocalDisplay(Thread):
def __init__(self, resolution):
...
def run(self):
...
def set_frame_data(self, frame):
....
def set_frame_data_padded(self, frame):
"""
Set the stream frame and return the rendered cropped face
"""
....
return outputImage
def greengrass_infinite_infer_run():
...
# Create a local display instance that will dump the image bytes
# to a FIFO file that the image can be rendered locally.
local_display = LocalDisplay('480p')
local_display.start()
# The sample projects come with optimized artifacts,
# hence only the artifact path is required.
model_path = '/opt/awscam/artifacts/mxnet_deploy_ssd_FP16_FUSED.xml'
...
while True:
# Get a frame from the video stream
ret, frame = awscam.getLastFrame()
# Resize frame to the same size as the training set.
frame_resize = cv2.resize(frame, (input_height, input_width))
...
model = awscam.Model(model_path, {'GPU': 1})
# Process the frame
...
# Set the next frame in the local display stream.
local_display.set_frame_data(frame)
# Get the detected faces and probabilities
for obj in parsed_inference_results[model_type]:
if obj['prob'] > detection_threshold:
# Add bounding boxes to full resolution frame
xmin = int(xscale * obj['xmin']) \
+ int((obj['xmin'] - input_width / 2) + input_width / 2)
ymin = int(yscale * obj['ymin'])
xmax = int(xscale * obj['xmax']) \
+ int((obj['xmax'] - input_width / 2) + input_width / 2)
ymax = int(yscale * obj['ymax'])
# Add face detection to iot topic payload
cloud_output[output_map[obj['label']]] = obj['prob']
# Zoom in on Face
crop_img = frame[ymin - 45:ymax + 45, xmin - 30:xmax + 30]
output_image = local_display.set_frame_data_padded(crop_img)
# Encode cropped face image and add to IoT message
frame_string_raw = cv2.imencode('.jpg', output_image)[1]
frame_string = base64.b64encode(frame_string_raw)
cloud_output['image_string'] = frame_string
# Send results to the cloud
client.publish(topic=iot_topic, payload=json.dumps(cloud_output))
...
greengrass_infinite_infer_run()
Save faces to S3 with an IoT Rule
The third IoT pillar intelligence interacts with the cloud pillar, which uses insights to perform actions on other AWS and/or external services. Our goal is to have all detected faces saved to an S3 bucket in the original JPEG format before we encoded it to Base64. To achieve this, we need to create an IoT rule that will launch an action to do so.
IoT Rules listen for incoming MQTT messages of a topic and when a certain condition is met, it will launch an action. The messages from the queue are analysed and transformed using a provided SQL statement. We want to act on all messages, passing on data captured by the DeepLens device and also inject the “unix_time” property. The IoT Rule Engine will allow us to construct statements that do just that, calling the timestamp function within a SQL statement to add it to the result, as seen in the statement below.
# MQTT message
{
"image_string": "/9j/4AAQ...",
"face": 0.94287109375
}
# SQL Statement
SELECT *, timestamp() as unix_time FROM '$aws/things/deeplens_topic_name/infer'
# IoT Rule Action event
{
"image_string": "/9j/4AAQ...",
"unix_time": 1540710101060,
"face": 0.94287109375
}
The action is an AWS Lambda function (seen below) that is given an S3 Bucket name and an event. At a minimum, the event must contain properties: “image_string” representing the encoded image and “unix_time” which used for the name of the file. The last property is not something that is provided when the IoT message is published to the MQTT topic but instead is added by the IoT rule that calls the action.
# File "src/process_queue.py" in code repository
import os
import boto3
import json
import base64
def handler(event, context):
"""
Decode a Base64 encoded JPEG image and save to an S3 Bucket with an IoT Rule
"""
# Convert image back to binary
jpg_original = base64.b64decode(event['image_string'])
# Save image to S3 with the timestamp as the name
s3_client = boto3.client('s3')
s3_client.put_object(
Body=jpg_original,
Bucket=os.environ["DETECTED_FACES_BUCKET"],
Key='{}.jpg'.format(event['unix_time']),
)
Deploying an IoT Rule with AWS SAM
AWS SAM makes it incredibly easy to deploy an IoT Rule as it is a supported event type for Serverless function resources, a high-level wrapper for AWS Lambda. By providing only the DeepLens topic name as a parameter for the template below, a fully event-driven and least privilege AWS architecture is deployed.
# File "template.yaml" in code repository
AWSTemplateFormatVersion: '2010-09-09'
Transform: 'AWS::Serverless-2016-10-31'
Parameters:
DeepLensTopic:
Type: String
Description: Topic path for DeepLens device "$aws/things/deeplens_..."
Resources:
ProcessDeepLensQueue:
Type: AWS::Serverless::Function
Properties:
Runtime: python2.7
Timeout: 30
MemorySize: 256
Handler: process_queue.handler
CodeUri: ./src
Environment:
Variables:
DETECTED_FACES_BUCKET: !Ref DetectedFaces
Policies:
- S3CrudPolicy:
BucketName: !Ref DetectedFaces
Events:
DeepLensRule:
Type: IoTRule
Properties:
Sql: !Sub "SELECT *, timestamp() as unix_time FROM '${DeepLensTopic}'"
DetectedFaces:
Type: AWS::S3::Bucket