Why use a Partner for your Cloud Services vs going Direct?
Unlocking the power of a partner, your path to success There are many cloud providers out there, such as AWS (Amazon Web Services, Microsoft/Azure, Google, etc), but how do you know which one to use and if you are getting the full benefits from them? Is going direct really the right option? Using a partner […]
Leveraging Data Platforms for Better ESG Reporting and Sustainability

Environmental, social, and governance (ESG) factors have become crucial considerations for businesses worldwide. ESG reporting enable companies to measure and communicate their impact on the environment and society, while ensuring good governance practices. To improve their ESG performance, more and more companies are turning to data platforms which allow them to collect, analyse, and report […]
Unlock the Power of Data with TechConnect and GDPR Compliance

What Is GDPR? The General Data Protection Regulation (GDPR) is an EU legislation enacted in May 2018 that establishes data protection as a fundamental right to UK and EU based users. It includes numerous provisions covering the use, storage, confidentiality, and transfer of personal data. This law ensures that privacy remains a priority, no matter […]
Achieving Success through Data-Driven Decision Making with the AWS D2E Program

Insights fromTechConnect’s COO As the COO of TechConnect, I have witnessed firsthand the incredible results that can be achieved with data-driven decision making. I recently participated in an AWS Data-Driven Everything workshop and was impressed with how the program moves beyond theoretical discussions to provide a structured approach to becoming data-driven. The AWS D2E program […]
The Importance of Data in the Business World

In today’s business world, data is more important than ever before. With the advent of big data and data analytics, businesses have been able to gain insights into their operations that were previously unavailable. By understanding their data, businesses can make better decisions, improve their products and services, and find new opportunities for growth. Here’s […]
Demystifying the AWS Datalake
AWS provides a rich ecosystem of services to employ in delivering data products. In fact, the number of services are so large that it can be daunting for an organisation to navigate the landscape. One of the guiding principles of cloud based Datalakes is the separation of compute resources from storage resources. In general, the […]
Cloud Governance and Compliance on AWS with Code

How AWS Control Tower customisation can assist in automating cloud infrastructure governance? Technology is the bedrock for almost every single industry out there. With that in mind, technology (specifically cloud based platforms) goes through a high rate of innovation and fast-paced evolution. The challenge these days is to deliver constant improvements while providing bedrock-like stability. […]
7 Steps to becoming a more Data-Driven company

Getting the best use from your data
Digital Transformation and Smart Cities

Digital Transformation and Smart Cities; are they the same thing? There has been much written about Digital Transformation and probably a similar amount regarding Smart Cities. This blog will explore some of these two concepts with the focus on Smart Cities within the context of Australian Local Government Authorities (LGAs). What should define a Digital […]
Migrating Relational Data into an Amazon S3 Data Lake

The concept of a data lake is not new, but with the proliferation and adoption of cloud providers the capacity for many companies to adopt the model has exploded. A data lake is a centralised store for all kinds of business data: unstructured – images, videos, PDFs, Word documents semi-structured – JSON, XML, spreadsheets structured – CSVs, RDBMS […]
What a hybrid workforce in 2021 means for your security and data strategy

Many workplaces spent 2020 suddenly working from the home. With this large shift to a remote workplace, many organisations were able to witness first-hand the ability to maintain productivity even when geographically dispersed. Where previously there had been a fear that separating the workforce would create a variety of insurmountable problems, 2020 showed us that […]
Chest X-Ray Triage using Artificial Intelligence Solutions
As a long term partner of IntelliHQ, a Queensland AI Hub consortium member, the TechConnect team was alerted to the Queensland AI Hub Medical datathon to be held over 2 weeks in June 2020. TechConnect is an AWS advanced consulting partner with a data science team whose experience spans from beginner to expert. As such, […]
How can businesses improve mobile customer experience?

GETTING CLOSER TO YOUR MOBILE USERS – NO MATTER WHERE THEY ARE IN THE WORLD. A couple of years ago one of our clients approached us with a difficult question: “How can we understand and improve mobile game performance and player experience in targeted locations around the World?” This was not easy to answer. Simulating […]
Digital Transformation with Data

Harnessing Data to drive effective digital transformation The COVID-19 pandemic has made clear that businesses need to be prepared for flexible, remote working practices. As lockdowns forced offices to close and people headed home to limit the potential spread of the virus, many organisations found they weren’t prepared to provision the necessary work from home […]
TechConnect achieves AWS Data and Analytics Competency

AWS Data and Analytics Competency Proves technical proficiency, operational excellence, security, reliability and 360-degree customer delivery capability; Cites major client projects with Virgin’s Velocity Frequent Flyer and IntelliHQ. TechConnect IT Solutions (TechConnect), a leading provider of cloud services and an Amazon Web Services (AWS) Advanced Consulting Partner, today announces it has been awarded AAWS Data […]
5 Mistakes to Avoid – When Migrating to the Cloud

Download a copy
AWS DeepLens: Creating an IoT Rule (Part 2 of 2)
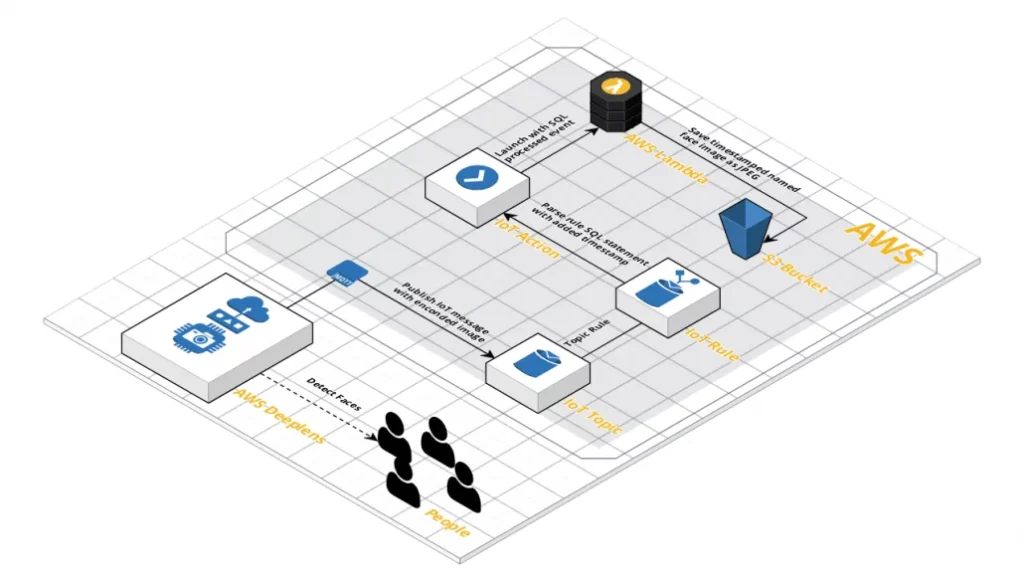
This post is the second in a series on getting started with the AWS DeepLens. In Part 1, we introduced a program that could detect faces and crop them by extending the boilerplate Greengrass Lambda and pre-built model provided by AWS. This focussed on the local capabilities of the device, but the DeepLens device is […]
AWS DeepLens: Getting Hands-on (Part 1 of 2)

TechConnect recently acquired two AWS DeepLens to play around with. Announced at Re:Invent 2017, the AWS DeepLens is a small Intel Atom powered Deep Learning focused device with an embedded High-Definition video camera. The DeepLens runs AWS Greengrass, allowing quick compute for local events without having to send a large amount of data for processing […]
Machine Learning with Amazon SageMaker

Computers are generally programmed to do what the developer dictates and will only behave predictably under the specified scenarios. In recent years, people are increasingly turning to computers to perform tasks that can’t be achieved with traditional programming, which previously had to be done by humans performing manual tasks. Machine Learning gives computers the ability […]
Precision Medicine Data Platform

Recently TechConnect and IntelliHQ attended the eHealth Expo 2018. IntelliHQ are specialists in Machine Learning in the health space, and are the innovators behind the development of a cloud-based precision medicine data platform. TechConnect are IntelliHQ’s cloud technology partners, and our strong relationship with Amazon Web Services and the AWS life sciences team has enabled […]
Using AWS SAM for a CORS Enabled Serverless API
Over the past two years TechConnect has had an increasing demand for creating “Serverless” API backends, from scratch or converting existing services running on expensive virtual machines in AWS. This has been an iterative learning process for us and I feel many others in the industry. However, it feels like each month pioneers in the […]